
 Dan
Dan2021. What an interesting year. With the world turned upside down by a pandemic that seemingly had its sights set on...

InfiniBand Wish List for the NonStop X
A pragmatic perspective of what NonStop IB should be Part 2 of 2
Caleb Enterprises Ltd.
 Dan
Dan
If you missed the first part of this series as published in the April 2017 issue of NonStop Insider, go here to read it first.
NonStop Architecture BottleNecks
Bottlenecks do exist within NonStop and among them, I call out the following:
- Guardian Inter-process messaging (IPM) is slow.
- Disk I/O is IPM-bound.
- Guardian processes will be able to communicate with hybrid platforms considerably faster than with other processes even within its own CPU. That sucks.
- NonStop checkpointing is a major drag on performance.
- TMF Audit is the ultimate SQL bottleneck.
While I have identified them as bottlenecks, for purposes of clarity, there have been no users of the new NonStop X family of systems that have expressed performance concerns to HPE. And yet, there is much that can be done to get even more performance from NonStop X particularly when addressing upcoming configurations likely to appear given HPE’s extensive promotion and pursuit of Hybrid IT.
In 1999, Angelo Pruscino (the key architect at Oracle who was then working on Oracle Parallel Server) told me that the observation of Oracle architects with regard to their event dispatcher is that with thousands of concurrent threads, throughput actually degraded to the point that it would take up to half a second for a thread to switch context. They also observed that as the number of processes increased, the performance degraded exponentially. This is the single biggest performance enhancement the OPS implementation resolved.
Clearly, eliminating context switching is very important. Just how expensive is it on NonStop NS7 servers though? Here are some actual performance numbers that put this in perspective. This is how fast a 1K message can be moved:
- DMA writes (as measured on a 6-core Xeon ProLiant DL360-G9) 181,818/second
- RDMA on a 56 Gb FDR switch 3,802,740/second
- Guardian IPM (tested on an NS7 server L15.08 with ping-pong test) 53,191/second
The first number was achieved with a pair of producer/consumer programs using XIPC on a DMA shared-memory segment in user mode with no context switching. The second number was presented by Mellanox at the MVAPICH Users Group conference in 1016 and is in Figure 2 of the first part of this article.. The third was documented with a ping-pong program that iteratively sent Guardian IPM messages between two CPUs as a producer and consumed those messages as a consumer on an otherwise idle server. I have run the tests on both NonStop System I (Itanium) node \BLITZ and NonStop X NS7 (x86) node \COGNAC2 servers when I was granted access to the ATC. At this time, however, I need to acknowledge that the HPE NonStop team has none of the five items above on their roadmap as best as I can tell, but this is at the heart of what I believe needs to be addressed.
If NonStop processes could be enabled to facilitate RDMA writes to a shared memory address space, the RDMA write rate would be very close to the DMA writes metric above. How do I know this to be true? InfiniBand latency across a single switch hop is 250 µs. Do the math.
250 / 1000000 * 181,818 = 45.4545
This means that RDMA would reduce the DMA throughput by only 45 messages per second. Contrast that with the enormous latency that Guardian IPM incurs. What is the bottom line behind why InfiniBand is so much faster than IPM? InfiniBand I/O does not require a context switch. It does all of its I/O within the time slice of the requesting process and remains in user mode at all times. The next figure illustrates the relative latency incurred by various I/O devices.
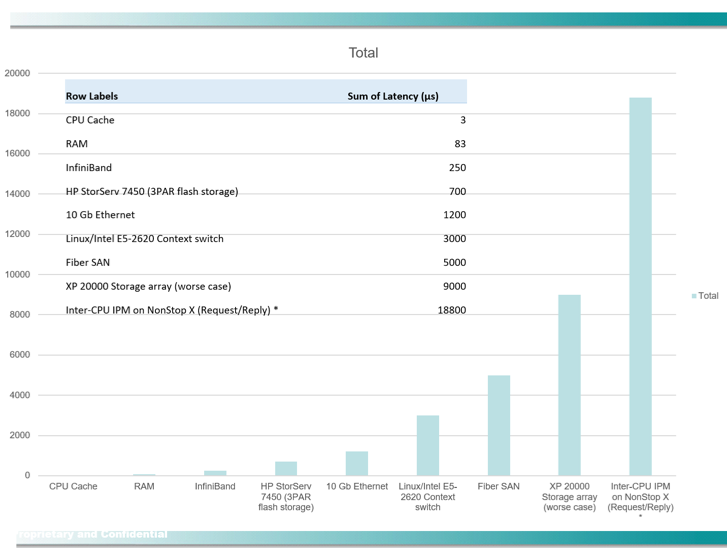
Figure 1 – Latency of Guardian IPM versus other devices
Per HPE’s own NSADI Reverence Manual, “In general, IB memory registration is relatively costly in that a kernel transition is required to perform the necessary translation and pinning of memory.” There you have it – another context switch. What this tells me is that one wants to allocate a giant segment of memory in a single operation and then manage that memory with code. Allocating and deallocating memory, queue pairs, etc. are a poor architecture decision. I wonder if there are any tools out there that provide such user-mode memory management services? Why yes! There are!
With what we have covered so far, we can now conclusively say that Guardian IPM is slow because it incurs context switching. When I benchmarked NS7 Guardian IPM, I ran the same tests on an Itanium blade and discovered that it was about five times slower than on the X server. Now you know the basis of the HPE claim that NSX is five times faster than Itanium. The InfiniBand fabric is fifty times faster than ServerNet. Interconnect fabric is not the differentiator here – at least not the main one.
As for inter-process messaging between NonStop processes and with hybrid server processes, it is simply unacceptable that Guardian processes can’t use IB to communicate with each other. It is even worse when inter-communication with an on-platform process is slower than with a process across a network. Again we turn to the NSADI Reference Manual; “Any external servers identified as running a rogue Subnet Manager will have their associated IB switch port disabled.” It is clear that HPE is locking down this architecture rather severely. Since the quote is in a section titled Security, then this is the asserted reason. But is this reasonable? IB is fundamentally IPV6 so that in theory, the network can be firewalled. I think this must be changed.
So now let’s take each of the 5 bottlenecks that I identified above and let’s propose an alternate solution:
IPM incurs a cost: I see two viable solutions here:
- Allow Guardian processes to communicate with each other via InfiniBand OFED QP (queue pairs) to eliminate the context switching.
- Incorporate InfiniBand I/O completion into AWAITIOX and modify it to favor servicing IB I/O completions over $RECEIVE up to a configurable time limit that can be established when $RECEIVE is opened.
Disk I/O is IPM-bound: This is obviously true because Disk I/O completes on $RECEIVE. It is just a specialized case of IPM but it has significant implications. Foremost is the obvious fact that if disk I/O becomes faster than IPM, then IPM becomes the bottleneck. Storage arrays are faster than IPM so this is an important performance factor that could be immediately leveraged.
NonStop IPM is outperformed by InfiniBand via QP: The solution here is for HPE to open up the InfiniBand architecture and implement an IB router so that all processes can discover and reference each other’s resources. As the NSADI Reference Manual states, “This NonStop implementation does not secure or encrypt data received from or sent to external customer servers. Security concerns must be addressed by client applications at a level above this layer.” HPE needs to add InfiniBand IPv6 packet routing.
NonStop Checkpointing is a Major Drag: When I implemented my fault-tolerant shared memory solution two decades ago, I used active NonStop checkpoint IPM messages at every critical region of processing. Every XIPC verb required three checkpoint IPM messages between the process pairs for every IPM request from a “client” user of our API – a total of 4 IPMs per RDMA operation. In my view, the elimination of this bottleneck is entirely feasible by doing the following:
- Establish a QP between the primary and backup process on which to send the checkpoint messages.
- Put the checkpoint message on the queue in the primary process and then immediately resume processing. There is no need to wait for “I/O completion” because if the QP Put fails, there will be an immediate error message.
- Because there is very little checkpoint drag and no blocking added, a NonStop process pair will be just as fast as a regular process.
- The NonStop process pair will rely on processing the $RECEIVE queue for session partner and CPU failure notifications, as is presently done. If the backup does not have all the checkpointed messages in the QP, it can discard the operation with the certainty that the primary could not have possibly sent the remote client a reply. If all checkpoint messages are received by the backup that is taking over, then a possible-duplicate may be sent. If a sequentially increasing sync ID is maintained by both processes in the pair and the answer is sent twice to the remote client, the duplicate sync ID will be detected by the receiver and the 2nd reply can be discarded. All of this recovery logic was built into XIPC
There you have it. No loss or duplication of messages and high-performance checkpointing for a fault-tolerant process implementation.
TMF Audit is an SQL Bottleneck: TMF audit trails are simply flat files that are endlessly appended with a stream comprised of the latest audited file marker with TID (transaction ID) correlation. All that is needed to ensure ACID properties is to get that audit I/O flushed to disk. That I/O moves to the audit disks via our old slow friend; IPM. If multiple disks can be allocated to audit, then cross-section audit throughput can be linearly scaled by the number of disks. If data disks are added to TMF overflow, throughput is compromised by contention with other disk I/O. The proposed solution is to write to a shared-memory appliance via InfiniBand instead. This solution must be able to survive any single point of failure and preserve ACID properties. If you can get the audit operation completed faster, the database throughput speeds up by that amount. I have devised a particular architecture which will be 100 times faster than the present TMF implementation. 10,000 TPS becomes a million. Hey, I thought only Oracle and Volt DB had that kind of performance! But on NonStop? Whodathunk? I may be willing to share it with the “right” party. Contact me if interested.
Wish List for NonStop and Hybrid Systems
Architects like to use frameworks because they solve many problems, enhance the application without additional effort, and they speed up development. Alas, what frameworks exist on NonStop to help me build my InfiniBand applications? Must I resort to using complex OFED verbs and build up all my functionality from scratch before I can even start solving my business problem? Heaven forbid! Maybe I’ll just wait until something comes along, or use something that is easier to build with. HPE sales and C-level executives, are you listening?
First and foremost and at the top of my wish list, I want some tools! What kind of tools?
- OpenSHMEM so I can attach to a shared memory region from any program implemented on any server with solid and rich synchronization mechanisms. HPE can implement the needed OFED tools and they or a third party can port the open source code. ***
- UPC so my NonStop processes can map to universal shared memory, regardless of where it resides and can interact with other processes on other operating systems. ***
- The rest of the OFED stack verbs need to be implemented so that open source frameworks like Mellanox VMA, Java tools and more can be easily ported to NonStop. ***
- Fault-tolerant shared memory. If this memory can be accessed by the processes of any operating system across any supported network transport, then so much the better! *
- Ability to aggregate a pool of memory across multiple federated servers as a single addressable region. **
- Firewall and SIEM tools that help me manage my IB network. ***
- Implement as much functionality as possible in user mode without incurring a context switch. It needs to perform! *
- A shared-memory transaction monitor (TM) that can emulate what Tuxedo does to participate in distributed transactions by preserving before and after images of sets of memory. It would be even better if the TM was directly integrated with that of the various operating systems and/or RDBMS engines. This would allow NoSQL database vendors to participate in transactions and open new vistas for customers.
- Middleware that can level the complexity of fault-tolerant versus conventional resources with a simple configuration file. The deployment should be completely seamless. The only business decision I should need to make is “Should this business function be fault tolerant or not?” *
- Robust security framework that can secure RDMA resources, right down to a particular range of memory, a message queue or a synchronization entity. This security framework must include both user authentication and business function authorization. If I open an application up to a million users, it must be secure. **
- Metrics and analytics built into the framework so it is easy to generate reports to capture the data and spot trends without having to write a bunch of code. Having a global variable that is implemented as a singleton and spins itself up at process initialization would be ideal. **
- Resource monitors for referencing distributed resources for debugging, monitoring and maintenance purposes. *
- Late binding to shared resources – like at runtime. If I wish to migrate resources to a different server, it must be easy and manageable. *
- A universal IPM framework that is platform agnostic. *
- Asynchronous I/O completion mechanisms in this distributed environment. Several come to mind: callback, event notification, waited, and waited with timeout. *
- Container deployment (think Docker etc.) so that large scale frameworks can be spun up and torn down quickly in a light-weight manner. **
- A solution that works over TCP/IP and IB seamlessly. If my customers want to access IB resources via their cell phones or from a browser over TCP/IP, then so be it. When the world eventually replaces TCP/IP with IB to the curb, I don’t want to re-engineer my application. **
* Already existing functionality in XIPC on all platforms
** Can be delivered within the year
*** What would best be offered/implemented by HPE
In other words, I want an IB-enabled framework that will be to RDMA what WebSphere MQ has become to guaranteed-delivery messaging. It works the same way on everything, everywhere, over every available network transport. The special value proposition of NonStop is that its memory will be fault-tolerant and will survive any single point of failure – what NonStop does best. Now that is what I call a hybrid framework!
Final Thoughts
I have built message switches, event dispatchers, message-oriented middleware products, 4GL frameworks, network transports, and participated in the construction of a significant number of large-scale applications and frameworks, so I have actually built many of the tools described in my wish list.
This is a tall order of wish-list items that I have proposed, but I am going to say boldly that with the right financial support, I can single-handedly deliver more than half the capabilities in this list within an existing framework (i.e. * and **) within a year. Indeed, a great deal of the needed code has already been written and runs on all the servers that industry cares about – including NonStop. A bonus? It even runs on Itanium NonStop!
Here comes the shameless plug. If anyone is interested in building a business application with a framework similar to what I have described in the wish list, please reach out to me. Several NonStop partners have liked what I have shown them but the bottom line is always the same when it comes to opening the checkbook; “Do you have a customer who would be willing to buy it?” That is a fair question. If a few prospective customers do come forward though, I will work diligently to bring this to market. With an NDA in place, what I can show you will be very impressive.
The first customer who is willing to commit as an early adopter to use the framework will win by obtaining extremely favorable pricing as an appropriate offsetting risk buffer. Most readers know what WebSphere MQ costs. Expect similar pricing – and savings. Second place commits need to pay more freight. Don’t think you will need to wait for months or years before you can start development either. We have the RDMA APIs available right now to start building applications on Windows, Linux, Solaris, AIX, Itanium & NonStop servers. Everything in the wish list with this * already works over TCP/IP. The rest of the capabilities with this ** will come in months – not years. If you want to see what 100,000 TPS looks like on a NonStop, hitch your wagon to these horses.
Contact me at dean@caleb-ltd.com or visit my web site. www.caleb-ltd.com
Dean E. Malone
