
 Dan
Dan2021. What an interesting year. With the world turned upside down by a pandemic that seemingly had its sights set on...

InfiniBand Wish List for the NonStop X
A pragmatic perspective of what NonStop IB should be and the value it would provide all NonStop users - Part 1 of 2
Caleb Enterprises Ltd.
 Dan
Dan
The cornerstone of any application is the architecture of the platform(s) – the foundation – upon which it is predicated. The architect’s job is to understand the foundation and to design a business solution that makes optimal use of that foundation. NonStop is a platform that has a particular architecture that is both its blessing and its curse. But what I am going to discuss can resolve the curse – once and for all.
The blessing is that it can survive any single point of failure because its core architecture is SNMP – Shared-nothing Multi Processor with redundant everything. The value proposition is that every program will have a backup running in another processor, or as a bare minimum, it will have a supervisor process that will ensure that if a process fails, it will be restarted in another processor. Furthermore, every component and data path is redundant so that if one fails, there is a backup to take over.
Its curse is that the predominant computer architecture of most competitive computers are predicated on SMP – Symmetrical Multi-processor – so programs that run on other servers don’t port well to NonStop. It’s simply too different. The key architectural attribute of these SMP computers that allows them to perform much faster than NonStop is shared memory.
If NonStop architecture could overcome this drag and still be able to survive any single point of failure, is it possible to win that stock market vertical back? Would this open the door to other market verticals? Is HPE’s “The Machine” architecture something that is likely to displace NonStop? Here is a thought. What happens to the data when a memristor fails? The answers are yes, yes, no and you’re screwed.
The key bottlenecks in NonStop architecture are:
- Guardian Inter-process messaging (IPM) is slow.
- Disk I/O is IPM-bound.
- Guardian processes will be able to communicate with hybrid platforms considerably faster than with other processes even within its own CPU. That sucks.
- NonStop checkpointing is a major drag on performance.
- TMF Audit is the ultimate SQL bottleneck.
The fundamental reason for this slow performance is exactly what makes the market perceive NonStop as a slow platform in general – context switching. It is the primary source of latency and IPM incurs context switching. Clearly, eliminating context switching is very important. Just how expensive is it on NonStop NS7 servers though? Here are some actual performance numbers that put this in perspective. This is how fast a 1K message can be moved:
- DMA writes (as measured on a 6-core Xeon ProLiant DL360-G9) 181,818/second
- RDMA on a 56 Gb FDR switch 3,802,740/second
- Guardian IPM (tested on an NS7 server with ping-pong programs) 53,191/second
The first number was achieved with a pair of producer/consumer programs using XIPC on a DMA shared-memory segment in user mode with no context switching. The second number was presented by Mellanox at the MVAPICH Users Group conference in 2016 and is in Figure 1. The third was documented with a ping-pong program that iteratively sent Guardian IPM messages between two CPUs as a producer and consumed those messages as a consumer on an otherwise idle server. I ran the tests on both Itanium and NS7 servers in the ATC, late one night in 2016.
What are the architectural gaps that need to be filled to meet the stated goal of fault tolerance with much less checkpoint and context switching latency drag? If NonStop architecture could overcome this drag and still be able to survive any single point of failure, is it possible to win the stock market vertical back? Would this open the door to other market verticals demanding high performance?
The leading edge of computer platform technology is High Performance Computing – HPC. I attended the MVAPICH Users Group (MUG) conference in August of 2016 to learn more about this technology and the key frameworks on which it is built, of which MVAPICH is a significant component. It is the industry’s best performing message passing interface – MPI. This interface includes many services that are found in the Guardian Procedures library. It is very impressive.
In attendance at the conference were some of the leading HPC platform hosts, including Lawrence Livermore Labs, Los Alamos Lab, Nvidea and their GPU software team, Intel’s interconnect architects, the VP of marketing for Mellanox and several of his team, and a host of other interesting people. If pictures are worth a thousand words, the next three included figures will speak volumes about the state of the art in HPC computing.
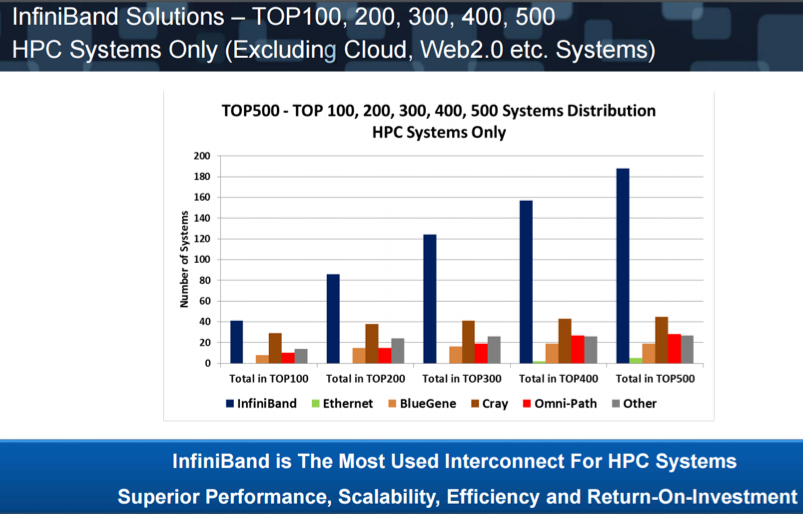
Figure 1 – Top 500 HPC Servers and their Interconnect Fabric
The first figure (above) shows the percentage of the world’s 500 fastest computers and the BUS fabric they use. It is no surprise that InfiniBand is by far the fabric of choice. Clearly, HPE is in good company in selecting InfiniBand for NonStop.
The next figure shows Mellanox’s HPC-X framework and where it fits into a computer’s architecture. Before showing what the framework is comprised of – several of the components of which are not yet implemented on NonStop – it is important to understand why it is important. This next slide was shown at MUG and I modified it to show how much TMF can theoretically be speeded up if HPE does the kind of architectural innovations around InfiniBand and RDMA that Oracle has done. If I am wrong about the 10,000 TPS limitation of NonStop, I am not wrong by an order of magnitude. I have not seen claims of faster throughput than this in years.

Figure 2 – OFED InfiniBand Versus InfiniBand with HPC-X Acceleration
I highlighted the 4K metric because this is the NonStop disk I/O blocking factor most often used. Wouldn’t it be amazing if NonStop disk I/O and audit trails in particular were this fast? More on that thought later.
Here is where the HPC-X tools fit into computer architecture in the next figure.

Figure 3 – Where Mellanox HPC-X fits in Computer Architecture
So what exactly are all of these HPC-X components? The following is a brief description:
MXM
- Mellanox Messaging (TP, DP and UP packets); accelerates RDMA puts/gets in hardware
FCA
- Fabrics Collectives Accelerations; accelerates underlying synchronization mechanisms in hardware
OpenSHMEM
- org-compliant Partitioned Global Address Space (PGAS) libraries
MPI
- high performance implementation of OpenMPI optimized to leverage Mellanox MXM & FCA
SHArP
- Scalable Hierarchical Aggregation Protocol; decreases the amount of data traversing the network and dramatically reduces the MPI operations time
UPC
- Unified Parallel C; Berkeley Unified Parallel C Project-compliant compiler; maps program symbols to distributed memory resources
- Includes Mellanox-optimized GASNET communication conduit
IPM
- Integrated Performance Monitoring
Of these products, several come for free if you use Mellanox InfiniBand equipment and drivers, so they are presumably included in the NonStop Mellanox switches. Is HPE leveraging this HPC-X framework? It is not important to be as fast as the second column within the NonStop enclosure because there is so much more bandwidth than the NS7 Server components could possibly use, but with a Hybrid environment of massive scale, it becomes a factor. But I know that several important components need to be ported to get the entire suite of capabilities. The most important are i) the UPC compiler, which should readily port to OSS and ii) OpenSHMEM, which needs a few more OFED verbs implemented before it can be ported to OSS. OpenSHMEM is open source code.
The importance of the UPC compiler is that it allows a local process to directly reference a remote RDMA buffer directly – similar to what shmat() does in allowing a program to reference shared memory with a pointer.
The importance of OpenSHMEM is that it provides an industry standard interface to universal shared memory. Martin Fink talked about that at 2015 HP Discover. I see an even more important use for NonStop – a fault-tolerant version of OpenSHMEM memory.
I am going to go out on a limb here. I believe that if HPE NonStop fails to capitalize on adding fault-tolerant shared memory to its core capabilities, it will lose its position as the premiere fault-tolerant platform.
If NonStop processes could be enabled to facilitate RDMA writes to a shared memory address space, the RDMA write rate would be very close to the DMA writes metric above. How do I know this to be true? InfiniBand latency across a single switch hop is 250 ns. Do the math.
250 / 1000000000 * 181,818 = .0454545
This means that RDMA would reduce the DMA throughput by less than 1 message per second. Contrast that with the enormous latency that Guardian IPM incurs. What is the bottom line behind why InfiniBand is so much faster than IPM? InfiniBand I/O does not require a context switch and there are no intermediate buffer copies. It does all of its I/O within the time slice of the requesting process and remains in user mode at all times. The next figure illustrates the relative latency incurred by various I/O devices.

Figure 4 – Latency of Guardian IPM versus other devices
Per HPE’s own NSADI Reference Manual, “In general, IB memory registration is relatively costly in that a kernel transition is required to perform the necessary translation and pinning of memory.” There you have it – another context switch. What this tells me is that one wants to allocate a giant segment of memory in a single operation and then manage that memory with code. Allocating and deallocating memory, queue pairs, etc. are a poor architecture decision. I wonder if there are any tools out there that provide such user-mode memory management services? Why yes! There are!
With what we have covered so far, we can now conclusively say that Guardian IPM is slow because it incurs context switching. When I benchmarked NS7 Guardian IPM, I ran the same tests on an Itanium blade and discovered that it was about five times slower than on the X server. Now you know the basis of the HPE claim that NSX is five times faster than Itanium. The InfiniBand fabric is fifty times faster than ServerNet. Interconnect fabric is not the differentiator here – at least not the main one.
As for inter-process messaging between NonStop processes and with hybrid server processes, it is simply unacceptable that Guardian processes can’t use IB to communicate with each other. It is even worse when inter-communication with an on-platform process is slower than with a process across a network. Again we turn to the NSADI Reference Manual; “Any external servers identified as running a rogue Subnet Manager will have their associated IB switch port disabled.” It is clear that HPE is locking down this architecture rather severely. Since the quote is in a section titled Security, then this is the asserted reason. But is this reasonable? IB is fundamentally IPV6 so that in theory, the network can be firewalled. I think this is unreasonable and must be changed.
In the second installment of this article to be published next month in Nonstop Insider, I propose concrete solutions to these Nonstop Architecture bottlenecks, present a wish list of tools and capabilities that architects would need to build robust hybrid solutions on NonStop and hybrid clusters that will perform at HPC performance levels, and finally, close with my thoughts on all of this.
Dean E. Malone
If you would like to reach out to me to discuss any of this, I can be reached at dean@caleb-ltd.com or swing by my web site at www.caleb-ltd.com
